前言
这是我的“对话体讲稿”的一个尝试。从我自己读它的感觉来看,这个尝试不是很成功(笑)。
大概是 Bob(作者化身)给 Alice(拟构的学习者)讲 SAM 的一个过程。
前置内容
Alice:后缀树和后缀自动机…听起来是很高端的一个东西呢。
Bob:嘛,其实它挺简单的。相信你已经学过AC自动机了吧?
Alice:嗯。
Bob:那我考考你,AC 自动机里面的 fail 是什么东西?
Alice:就是失配的时候跳转的地方啊,这有什么问题吗?
Bob:不不不,不要用“失配”这个动词,你试试只用AC自动机来描述这个 fail 节点到底指向哪里。注意,Trie 的每个节点对应于从根到它的一个字符串。
Alice:就是失配节点啊…从字符串上来看,是原本节点的一个后缀。
Bob:哪个后缀呢?
Alice:唔,应当是最长后缀。重复一遍:
在 AC 自动机中,节点 \(u\) 的 fail,是这样的一个节点 \(v\):
- \(v\) 是 \(u\) 的真后缀;
- \(v\) 出现在了 Trie 中;
- \(v\) 是所有满足上两条的字符串中最长的。
后缀 Trie 的引入
Alice:所以,什么是后缀自动机呢?
Bob:先别急嘛。先考虑这么一个问题:“\(t\) 是否是 \(s\) 的子串?”以你现在学过的字符串算法,你会做吗?
Alice:(有点生气)你在逗我吗…这随便做一下 KMP 不就好了吗。
Bob:那如果有很多不同的 \(t\),你会怎么办?
Alice:这不是把所有 \(t\) 扔进一个 AC 自动机吗。
Bob:那,如果 \(s\) 是提前给定的,但 \(t\) 是强制在线一个个给你的,你要怎么处理?
Alice:这…我不会。
Bob:提示:这个 \(s\) 的长度无关紧要,你只需要考虑对 \(\sum_{}^{}\!\left| t \right|\) 的复杂度。
Alice:那是不是把 \(s\) 的 \(O\!\left( \left| s \right|^{2} \right)\) 个子串全部扔到一颗 Trie 里面去就好了?这样对 \(t\) 的复杂度就是线性了。
Bob:Bingo。但你注意到这 \(O\!\left( \left| s \right|^{2} \right)\) 个子串形成的 Trie 仅仅只要考虑 \(O\!\left( \left| s \right| \right)\) 个后缀,其他的都是后缀的前缀、因而不用单独再插入。
Alice:没错,那么这个算法就是 \(O\!\left( \left| s \right|^{2} \right)\) 的。
Bob:那么我们如果把问题变成 “\(t\) 和 \(s\) 的最长公共子串是什么”怎么做呢?
Alice:唔…(思考中)只要把 Trie 变成 AC 自动机就好了吧。
Bob:没错。
Bob:我们今天要介绍的第一个数据结构,就是这个平方复杂度的东西,不如叫它“后缀
Trie”。
Bob:以串 mississippi 为例,我们把这个后缀 Trie
画一下:
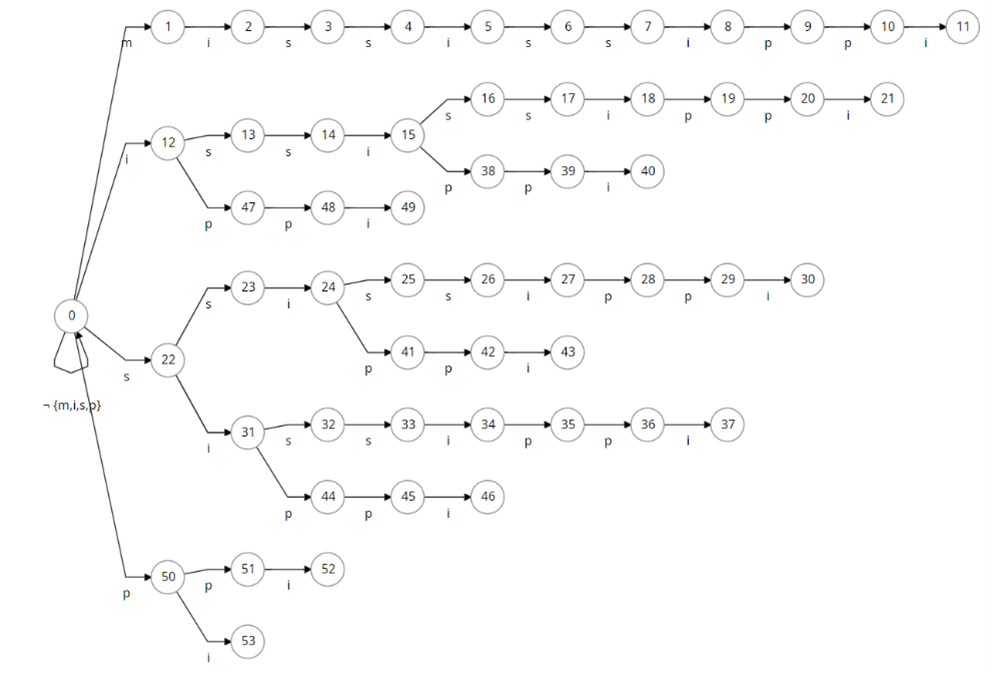
Bob:我问你,这颗 Trie 上的 fail 是什么东西?
Alice:唔,是刚才说的最长的后缀呢…
Alice:啊,但由于去掉第一位的后缀一定存在,所以最长后缀就是去掉第一位得到的
\(n - 1\) 长度的后缀。
Bob:没错。我们来考虑这棵 Trie 的结构:对于一个节点来说,假设它所代表的字符串是 \(u\),那么它的父亲所代表的字符串就是 \(u\left\lbrack 1\ldots\left| u \right| - 1 \right\rbrack\),也就是去掉最后一个字符;如果这是 AC 自动机,它的 fail 指向的字符串是 \(u\left\lbrack 2\ldots\left| u \right| \right\rbrack\),也就是去掉第一个字符。
我们也可以发现,父亲的 fail 等于 fail 的父亲。
Bob:这个“父节点-fail节点”之间有一种对称性。我们换一种方式来描述:考虑一个串 \(u\) 的后缀 Trie \(T_{u}\),它的 fail 也形成了一个树结构;再考虑 \(u\) 的翻转 \(\mathrm{\mathrm{rev}}\left( u \right)\) 的后缀 Trie \(T_{\mathrm{\mathrm{rev}}\left( u \right)}\),原串的 fail 树恰好和翻转的 Trie 是一样的。
精确地说,存在一个节点间的双射 \(r:T_{u} \rightarrow T_{\mathrm{\mathrm{rev}}\left( u \right)}\),使得\(\ \forall x \in V\!\left( T_{u} \right),\ r\!\left( \mathrm{\mathrm{fail}}\!\left( x \right) \right) = \mathrm{\mathrm{fa}\!}\left( r\!\left( x \right) \right)\),其中 \(V\) 代表节点集合。很显然,这个 \(r\) 所做的事情就是把字符串翻转。
后缀 Trie 的压缩
Alice:那这和后缀自动机有什么关系呢?
Bob:Alice 你别急嘛,你已经第三次这么问了。这个后缀 Trie,不仅需要 \(O\!\left( n^{2} \right)\) 的时间构建,还需要\(O\!\left( n^{2} \right)\ \)的空间来储存节点,就很慢你看看之前画的那张图,是不是有很多长链?
Alice:对。是不是可以把长链压到一起?
Bob:完全正确。一个串只有 \(\left| s \right|\) 个后缀,那么后缀 Trie 也只有\(\left| s \right|\) 个叶子,而有很多点只有一个孩子。那我们只需要把一连串只有一个孩子的单链压缩到一起就可以了;如果每个节点都至少有两个孩子,这样的节点数就是 \(O\!\left( n \right)\) 的。举个例子来说,上图的 32~37 号节点就是一大条单链,我们可以完全压缩成一个节点(下图 5 号)。我画一下。
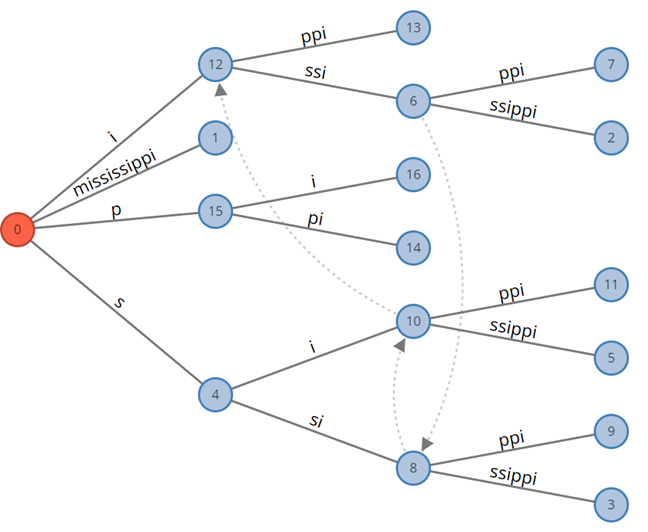
Bob:我们显然也不能在节点上存整个字符串,否则空间复杂度并没有降下来;但由于每条边上的这个字符串都是原串的一个子串,我们可以只存储这个子串的左右位置,因此我们得到了一个空间复杂度正确的结构。比如说,上图有很多
ssippi,我们可以只存储它是 \(s\!\left\lbrack 6\ldots 11
\right\rbrack\)。这样存储边之后,这个东西就叫做“后缀树”。
Bob:仔细想一想我们是怎么压缩的。我们把原 Trie 的 32~37 都压缩到了一起;也就是说,我们可以把一个只有一个孩子的节点压缩到它的孩子上。
在一棵树上,为了精确地捕捉“把一个只有一个孩子的节点压缩到它的孩子上面”这样的概念,我们形式地定义一下。对于一棵树 \(T\),在 \(T\) 的所有节点上定义一个等价关系,称 \(u,v\) 等价,当且仅当【\(u\) 子树中的所有叶子节点的集合】与【\(v\) 子树中的所有叶子节点的集合】相同。显然这样定义的 \(u,v\) 只相差一条单链。把一个等价类缩成一个节点,我们就可以得到一棵树的长链压缩形式。
我们把树的用语翻译到后缀 Trie 上。子树即祖先关系是前缀关系,叶子是后缀。那么“\(u\) 子树中的所有叶子节点的集合”就对应于“包含 \(u\) 为前缀的原串后缀的集合”。假设 \(s\!\left\lbrack i\ldots\left| s \right| \right\rbrack\) 是包含 \(u\) 为前缀的原串后缀,这意味着 \(s\!\left\lbrack i\ldots i + \left| u \right| - 1 \right\rbrack\) 恰好是 \(u\)。换句话说,我们用 \(\mathrm{\mathrm{Left}}\!\left( u \right)\) 表示 \(u\) 在原串中的所有出现位置的左端点集合,那么我们有 \(\mathrm{\mathrm{Left}}\!\left( u \right) \subseteq \mathrm{\mathrm{Left}}\!\left( \mathrm{\mathrm{fa}}\!\left( u \right) \right)\),两个串被压到一起当且仅当他们的 \(\mathrm{Left}\) 集合相同。
我们再来讨论后缀 Trie 上的 fail 会怎么作用到后缀树上。上图中,我们只画出了分叉的非叶节点,也就是同一个等价类中最深的节点。一个节点分叉,也就是说它对应的字符串在原串中后面跟的字符可能有多种;比如说在
mississippi中ssi的后面可能是s或者p。那么,如果一个子串有多种后继字符,那么它的 fail 显然也有多种后继字符,因此也是分叉的。因此,分叉的非叶节点的 fail 也是分叉的非叶节点。
Alice:(残念)你讲了这么多后缀树,那么后缀自动机是什么呀?
Bob:这不马上就讲到了吗。你再看看我给你画的后缀 Trie 的图,你感不感觉这里面有很多长得很像的东西?
Alice:感觉有很多节点的子树的结构都是一模一样的,比如说15、24、31。
Bob:确实。我们考虑把一样的节点直接指针指向同一个,比如说
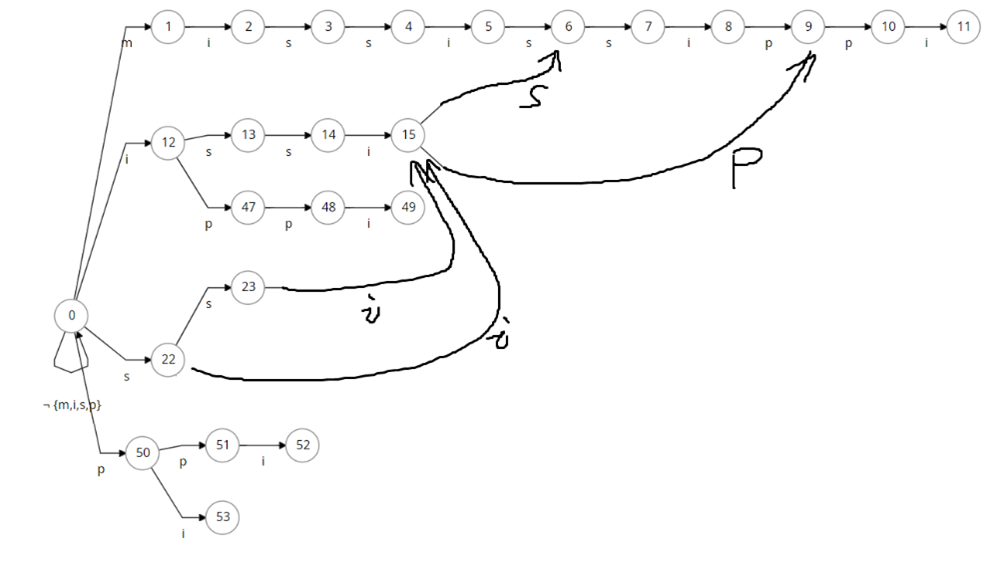
Bob:这样是不是也可以压缩这个 Trie 结构?
Alice:是的呢,但看起来还有很多可以压缩的。
Bob:对,而且这一步理解比较不直观。但我们在研究后缀树的时候已经使用了一种稍微抽象一点点的方法来表述,因此我们故技重施:
对于我们的后缀 Trie ,我们称两个节点等价,指他们的子树的样子(包括边上的字母)相同。这样的等价关系所形成的等价类就是后缀自动机的结点。那怎么表述子树的样子完全一样呢?如果 \(u\) 和 \(v\) 的子树一样,那么,对于所有 \(ux\) 是叶子,有 \(vx\) 也是叶子,反之亦然。换句话说,\(u\) 在原串中出现的所有右端点,也同样是 \(v\) 的右端点;反之亦然。那么很自然,我们可以定义 \(\mathrm{\mathrm{Right}}\!\left( u \right)\) 表示一个子串出现的右端点位置的集合,然后用这一集合建立等价类,然后将原树的边加上去,得到一张 DAG,这就是后缀自动机(SAM)。
Bob:可以看这张图。

Bob:我们再来讨论后缀自动机和 fail 有什么互动。在原树中,5、15、24、31、12是一条 fail 链,而其中的15、24、31拥有相同的 \(\mathrm{\mathrm{Right}}\),被压缩了起来:这启示我们后缀自动机实际上是依据 fail 压缩。就像 \(\mathrm{\mathrm{Left}}\!\left( u \right) \subseteq \mathrm{\mathrm{Left}}\!\left( \mathrm{\mathrm{fa}}\!\left( u \right) \right)\) 一样,我们有 \(\mathrm{\mathrm{Right}}\!\left( u \right) \subseteq \mathrm{\mathrm{Right}}\!\left( \mathrm{\mathrm{fail}}\!\left( u \right) \right)\);因此,就像后缀树压缩的是原树上一条不分叉的链一样,后缀自动机压缩的是 fail 树上一条不分叉的链;进而考虑其翻转对偶性质,我们可以得到知名结论“后缀自动机的 fail 树是反串后缀树”。
Alice:诶,就这?
Bob:(敲了敲Alice的头)
构建
Alice:那这两个东西空间线性我知道了,时间怎么整呢?
Bob:接下来我们来讲讲两个算法怎么构建。我们来考虑增量的构建方式,每次在原串末尾增加一个字符,更新相关结构。
后缀 Trie 的每步 \(O\!\left( n \right)\) 增量构建非常简单,只要在原来每个后缀后面加入那个新的字符就好了;那我们需要一种方法来枚举所有的后缀。但我们有 fail 指针,而一个后缀的 fail 指针就是比它短 1 的后缀,因此我们只需要从整个串开始不断沿着 fail 跳就可以找到所有的后缀。
- 从只有一个节点的树和空串开始。指针 \(p\) 表示整个串的节点位置(比如图1的结点11),指针 \(\epsilon\) 指向根。
- 每次增加一个字符 \(c\)
的时候,循环:
- 最初令循环变量 \(q\) 等于 \(p\)。
- 如果 \(q\) 没有 \(c\) 孩子,给 \(q\) 增加一个 \(c\) 孩子,并令 \(q \leftarrow \mathrm{\mathrm{fail}}\!\left( q \right)\),继续循环。
- 如果 \(q\) 已经有 \(c\) 孩子了,那么结束循环。让 \(p \leftarrow \mathrm{\mathrm{child}}(p,c)\)。
这个构建方法非常简单,但显然是 \(O\!\left( n^{2} \right)\) 的。
Bob:然后我们接着来考虑后缀树的增量构造。我们还是以刚才那个串为例,假设你加一个字符
p,那么后缀 Trie 上的 11、21、30 一直到 53
等一众叶子都会增加一个 p 孩子,直到 12 已经有了一个
p
孩子为止。在后缀树上,这些叶子加孩子的过程其实都可以忽略:只需要把所有叶子都标记成
\(\left\lbrack l, + \infty \right)\)
就可以了,这是我们的第一个发现。那我们并不需要记录这个 \(p\) 变量,只需要记录从“\(p\) 开始跳
fail,跳到的第一个非叶结点”就可以了。
- 从只有一个节点的树和空串开始。指针 \(r\) 表示“从 \(p\) 开始跳 fail,跳到的第一个非叶结点”。
- 每次增加一个字符 \(c\)
的时候,循环:
- 最初令循环变量 \(q\) 等于 \(r\)。
- 如果 \(q\) 没有 \(c\) 孩子,给 \(q\) 增加一个 \(c\) 孩子(它必然是叶子),并令 \(q \leftarrow \mathrm{\mathrm{fail}}\!\left( q \right)\),继续循环。
- 如果 \(q\) 已经有 \(c\) 孩子了,那么结束循环。让 \(r \leftarrow \mathrm{\mathrm{child}}(q,c)\)。
这一段伪代码看起来非常干净,但实际上我们要考虑一个问题:\(r\) 并不一定是一个后缀树的节点,而可能是后缀 Trie 的一个节点、被压缩在后缀树的一个位置。我们维护 \(r\) 的时候实际上需要维护“某个节点的入边的第某号位置”,而创建孩子的时候需要把那个分叉点也建出来。所以你需要实现一点点细节。
Alice:是亿点点细节吧喂!
Bob:(无奈地忽略)好,我们再来考虑后缀自动机的增量构造。由于“后缀自动机的 fail 树是反串后缀树”,我们先来考虑对后缀树做向前插入会发生什么:往后缀 Trie 里面增添一个新的后缀,增加至多一个叶子,那么会至多增加两个节点;这两个节点中一个是叶子,另一个是根到这个叶子的路线上第一次分叉的地方。再考虑对偶性,对 SAM 做末尾插入也会新建至多两个节点,第一个对应于后缀 Trie “长出新叶子”的部分,第二个对应于后缀 Trie 的“已经有这个孩子、但 \(\mathrm{Right}\) 集合不同,需要拆分等价类”的部分。伪代码这里就不放了,网上到处都是。(跑)
Alice:大鸽子,举报了!
参考资料
文章中用来做图的材料分别是 https://brunorb.com/aho-corasick/ 、https://brenden.github.io/ukkonen-animation/ 、https://github.com/SirNickolas/dawgviz 。